✅ Hash Table (해시 테이블)란?
해시 테이블은 Key-Value로 데이터를 저장하는 자료구조 중 하나로 빠르게 데이터를 검색할 수 있는 자료구조다. 해시 테이블이 빠른 검색속도를 제공하는 이유는 내부적으로 배열(버킷)을 사용하여 데이터를 저장하기 때문이다. 해시 테이블은 각각의 Key에 해시함수를 적용해 배열의 고유한 index를 생성하고, 이 index를 활용해 값을 저장하거나 검색하게 된다.
- 해시 테이블(hash table)
key-value를 넣으면 해시함수를 거쳐 인덱스로 변환 후 저장하는 자료구조 - 해시함수(hash function)
key를 (저장소의) index로 바꾸는 함수 - 해싱(hashing)
해시함수를 통해 key를 index로 바꾸는 작업 - 해시값(hash value)
index (key에 해시함수 적용한 것)
🖋 해시함수 (hash function)
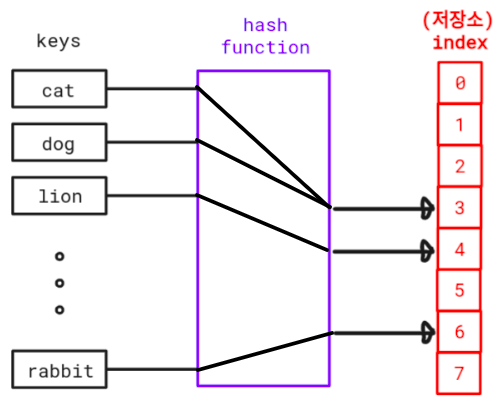
해시함수에 대해 조금만 더 깊이 알아보자.
해시함수란 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수다.
이 때, 매핑 전 원래 데이터의 값을 key(키), 매핑 후 데이터의 값을 해시값, 매핑하는 과정을 해싱이라고 한다.
이러한 해시함수의 특징으로는
- 출력된 결과 값을 토대로 입력값을 유추할 수 없다. (보안성)
- 동일한 값이 입력되면 언제나 동일한 출력값을 보장한다.
- 저장소(배열)의 크기를 알아야 유효한 인덱스(해시값)를 반환할 수 있다.
🖋 해시 테이블 (hash table)
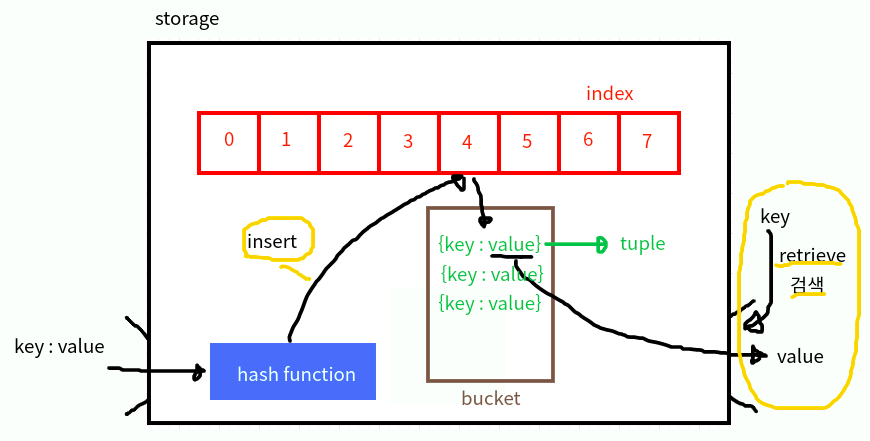
해시테이블은 실제로 데이터를 저장하는 공간이다.
원래 데이터가 해시함수를 거쳐 인덱스화가 되면 그 인덱스가 가리키는 공간에 value를 저장한다.
관련된 용어들이 다음과 같이 존재한다.
- hash table
데이터의 저장 공간 - storage
배열 형태의 저장소 - bucket
storage의 내부 저장소, 각 index마다 하나의 bucket을 가진다. - tuple
key-value가 직접적으로 저장된다. (읽기 , 덮어쓰기만 가능)
위 그림을 예시로 저장하는 과정을 따라가보자.
- key-value를 저장하고 싶다.
- 해시함수를 통해 key가 (storage의)인덱스화 된다. (해싱)
- storage에 해당하는 인덱스의 bucket에 tuple형태로 저장이 된다.
역시 글로보는 것보다 코드로 직접확인하는 것이 눈에 더 잘 들어올 것이다.
사람들마다 표현하는 방식이 다르지만, 내가 이해하기 쉽게
storage는 [], bucket은 {}, tuple은 객체(bucket)의 키-값쌍으로 표현할 것이다.
let storage = [
{key1: value1},
{},
{},
{key2: value2},
{},
{},
{},
{key3: value3, key4: value4]
]
중요한 점
- key-value를 저장할 때, 동일한 key를 가지면 안된다.
데이터를 저장 시 해시함수를 거쳐 key를 인덱스로 변형 후 key-value를 그대로(tuple)로 bucket에 저장하는데, 이 말은 즉 key가 같다면 기존의 value는 사라지고 새로 입력한 데이터(같은 key)의 value를 덮어씌우게 된다. - key는 다른데 같이 인덱스에 저장이 된다면? ➡ 해시 충돌(Collision)
🖋 해시 충돌 (Collison)
위에서 말했듯이 다른 key값을 가지지만 동일한 해시값(index)를 가질 때, 해시충돌이 발생한다.
이를 해결하기 위해 대표적으로 체이닝(chaining), 개방 주소법(open addressing)이 있다.
1. 체이닝(Chaining) = Closed Addressing
버킷 내에 연결리스트(linked list)를 할당하여, 버킷에 데이터를 삽입하다가 해시 충돌이 발생하면 연결리스트로 데이터들을 연결하는 방식
2. 개방 주소법(Open Addressing)
체이닝의 경우 버킷이 꽉 차더라도 연결리스트로 계속 늘려가기에, 데이터의 주소값은 바뀌지 않는다.
개방 주소법의 경우에는, 해시 충돌이 일어나면 다른 버켓에 데이터를 삽입하는 방식
🖋 해시 테이블 메서드 (Method)
insert(key,value) : 키, 값을 해시테이블에 저장
retrieve(key) : 키를 입력하면 해당하는 값을 반환
remove(key) : 해당 key의 데이터를 삭제
_resize : 배열의 사이즈를 키우거나 줄임 (필요시에만 늘리고, 가능한 작게 유지 (25~75%))
'Computer Science > Data Structure' 카테고리의 다른 글
| Graph (그래프) (0) | 2021.01.24 |
|---|---|
| Linked List (연결 리스트) (0) | 2021.01.22 |
| Stack&Queue (0) | 2021.01.20 |



댓글